
In this paper, we present the challenges involved in developing a mobile version of a neural machine translation system. The goal is to maximize the translation quality while minimizing the model size. We explain the entire process of implementing the translation engine using the English-Spanish language pair as an example. We describe the challenges encountered and the solutions implemented.
The main methods used in this work include:
- Data selection using Infrequent n-gram Recovery;
- Adding a special word to the end of each sentence;
- Generating additional samples without final punctuation.

The last two methods were developed to create a translation model that generates sentences without a final period or other punctuation marks. Infrequent n-gram Recovery was also used for the first time to create a new corpus, rather than just to augment a dataset in a domain.
Finally, we arrive at a small-sized model that provides good enough quality for daily use.
The Lingvanex Approach
Lingvanex is a brand of linguistic products by Nordicwise LLC, which specializes in offline translation and dictionary applications for both mobile and desktop platforms. In collaboration with Sciling, a company specializing in end-to-end machine learning solutions, a small English-Spanish translation model was developed for mobile use. The main goal was to provide accurate translations in everyday scenarios, especially for travelers who may not have access to the Internet due to roaming costs, lack of local SIM cards, or poor connectivity in certain areas. To achieve this, the project focused on minimizing the model size using data selection techniques, targeting a final size of 150 MB or less.
Experiments were conducted to identify key factors affecting model size, including vocabulary size, word embedding, and neural network architecture. Several translation issues arose during the implementation process, prompting the development of appropriate solutions. The quality of the final model was evaluated against leading mobile translators from Google and Microsoft, demonstrating its effectiveness for practical use in travel situations.
Data Description
The data used to train the translation model was obtained from the OPUS corpus. There were 76 M parallel sentences in total. We also used the Tatoeba corpus for DS described in the Data Filtering Section. Tatoeba is a free online collaborative database of example sentences aimed at language learners. The development set was also created from the Tatoeba corpus by selecting 2k random pairs of sentences. The main metrics of the Tatoeba corpus are shown in Table 1. As a test set, we create a small corpus of more useful English sentences found on different websites. We also add some unigram and bigram sentences. In total, we selected 86 sentences.

Model size dependency
When solving the problem of model size reduction, the main challenge is to determine which hyperparameters have the greatest impact on the size. Before implementing the neural machine translation (NMT) system, experiments were conducted comparing the model size with the overall vocabulary size and word embedding size (Figure 1). Different models were trained by varying these hyperparameters.

In the initial experiment, the recurrent layer had 128 units with one layer on both the encoder and decoder sides. The combined vocabulary sizes (V) (source and target) were reduced to different levels |V| = {5k, 10k, 20k, 50k, and 100k} based on the most frequent words in the Opus corpus with equal distribution between the source and target vocabularies, with source and target vocabulary size set to |V|/2. In addition, different embedding sizes |ω| = {64, 128, 256, 512} were analyzed.
The effect of different hidden units and number of layers was then examined while the embedding size was fixed at |ω| = 128. The results showed that the number of layers had a minimal impact on the model size, especially compared to the number of hidden units and embedding size. This analysis provides a basis for choosing appropriate hyperparameter values while keeping the model size within the target of 150 MB.
Data Filtering
Data filtering consisted of two main steps. First, sentences longer than 20 words were removed, as mobile translators are designed to translate short sentences. Second, data selection was performed using Infrequent n-gram Recovery. This technique aims to select sentences from the available bilingual data that maximize n-gram coverage within a smaller, domain-specific dataset.
The approach involved sorting the full dataset by the infrequency score of each sentence to prioritize the most informative ones. Let χ represent the set of n-grams in the sentences to be translated, and w denotes one of these n-grams. C( w ) indicates the number of w in the training set of the source language, while t is a threshold for determining when an n-gram is considered uncommon. N( w ) refers to the number of w in the source sentence f. The infrequency score of f is (1):

For the 60 million sentences from the Opus corpus, up to 5 n-grams were extracted from the Tatoeba corpus, aiming for a maximum of 30 occurrences for each n-gram. To manage runtime, the corpus was divided into six partitions, with selection performed individually before merging the results. A final selection process was performed to ensure that no n-gram exceeded the occurrence threshold. Ultimately, this process resulted in a dataset of 740,000 sentences with a vocabulary size of 19,400 words in the source language and 22,900 words in the target language, resulting in a combined vocabulary of 42,400 words. The sample was based on the tokenized and stringified corpus.
Experimental setup
The system was trained using the OpenNMT deep learning framework, which focuses on developing sequence-in-sequence models for a variety of tasks including machine translation and summarization. Byte Pair Encoding (BPE) was applied to a selected training dataset and then used for the training, development, and testing data. A long short-term memory (LSTM) recurrent neural network was used, including a global attention layer to improve translation by focusing on specific parts of the source sentence. The input feed was also used to provide attention vectors to subsequent time steps, although this only had a noticeable effect with four or more layers.
Training involved 50 epochs using the Adam optimizer with a learning rate of 0.0002. The best model was selected based on the highest BLEU score on the development set and was used to translate the test set. Due to the small size of the test set, human evaluation was performed to assess the quality of the translations.
Result and analysis
We trained different types of neural networks based on the ideas in the Model size dependency Section. In each experiment, we adjusted the hyperparameters while keeping the total vocabulary size fixed at 42.4k words. Table 2 shows the hyperparameter values for each experiment, as well as the BLEU scores and model sizes.

The best-performing model, as measured by the BLEU score on the development set, had 2 layers and 128 units in the recurrent layer with an embedding size of 128. Notably, this model was also the smallest among those listed in Table 2.
Problems found and their solutions
Analysis of the translations from the test set revealed three key problems, for each of which specific solutions were proposed.
1. Repeated Word Problem
The best model produced correct translations for sentences longer than seven words, but often generated repeated words in very short sentences (e.g., “ perro perro perro ”). This problem was due to the difference in sentence length between the training and test data, as the training set contained few short sentences (Figure 2).
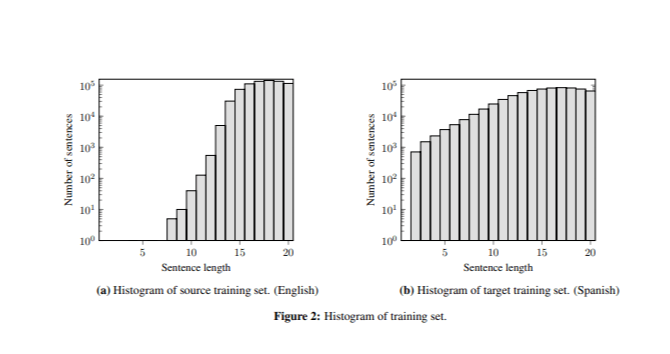
To mitigate this, we adjusted the Infrequent n-gram Recovery scoring function by adding a normalization step (2).

After applying unfrequency scoring for data selection, we selected a dataset of 667,000 sentences. In Table 3 we show the average sentence length in the source and target languages before and after applying sentence length normalization.

The normalization process allowed us to achieve significantly shorter sentences in both the source and target languages. The model achieved a BLEU score of 36.3 during development and 22.8 during testing, with a total model size of 121 MB. Although these scores are slightly lower than in previous experiments, we believe that BLEU may not always be the best indicator of translation quality. Manual analysis confirmed that the problem of repeated words was effectively solved.
2. Punctuation Mark Expectation
The model produced incorrect translations for very short sentences (e.g. translating "dog" as "amor") unless a punctuation mark was added (e.g. "dog".). This was due to the model's expectation of punctuation at the end of sentences; 94% of training sentences ended with a punctuation mark. Two solutions were proposed to address this issue:
- Special word ending: We added a special token @@ at the end of each sentence. This approach trains the model to recognize that each sentence ends with @@, while the penultimate word may or may not be a punctuation mark. This technique was implemented as a pre- and post-processing step, hence it is called special word ending. The model using this technique achieved a BLEU score of 36.4 in development and 26.3 in testing after 21 epochs, with a size of 121 MB.
- Dual corpus: We expanded the training corpus by combining all existing sentences that ended with punctuation marks, removing these characters. This allowed the model to learn that sentences can end with or without a punctuation mark. In this case, the model size increased to 156 MB, achieving a BLEU score of 37.3 in development and 25.1 in testing.
Both methods effectively solved the punctuation expectation problem;
However, due to the larger size and lower BLEU score of the dual corpus strategy, we decided to use a special word ending technique.
3. Missed segments
It was noted that when translating segments containing multiple short sentences, only the first of them was translated (e.g., "Thank you. That was really helpful." became "Gracias.").
To address this, a preprocessing step was introduced to separate segments based on punctuation marks. This adjustment increased the number of segments from 86 to 118 in the test set. After this change, the translations improved significantly, achieving a BLEU development score of 36.4 and a test score of 33.7, the highest recorded to date.
Final evaluation
Table 4 summarizes the BLEU scores obtained after applying each of the solutions described in Problems found and their solutions Section. After applying the normalized unfrequency score, the special word ending, and the preprocessing of the constructed sentences, we improved the quality of the test set by about 7 BLEU points.

In the final evaluation of our translation system, we compared its quality with Google and Microsoft mobile translators. Table 5 presents the BLEU scores and model sizes for each translator in the test set.

Overall, all three systems produced high-quality translations, although some minor differences were noted. Our model performed particularly well with punctuation marks and capitalization, while Google Translate often misplaced punctuation marks and used capitalization infrequently. This may explain why Google Translate received a lower BLEU score compared to the other two systems, despite its smaller model size. Additionally, Google and Microsoft’s models are bidirectional, which means that our model size needs to be doubled (2 × 121 MB) for a fair comparison.
Conclusion
This paper describes the development of a compact mobile neural machine translation for English-Spanish. We used a data selection method to improve the fitness of the training data and made adjustments to improve the translation quality. Solutions were proposed to address the issues of repeated words and missing translations in segments. Our model outperformed Google and Microsoft mobile translators in BLEU scores, especially in handling punctuation and capitalization. At 121 MB, our model is smaller than initially estimated, while still providing good translation quality for travel-related contexts. Translations are smooth and understandable, suitable for offline use. Current efforts are focused on further improving the quality and reducing the size of the model, including methods such as weight reduction.


